

New photometric survey classification given by machine learning method
The Javalambre Photometric Local Universe Survey (J-PLUS), conducted by the Observatorio Astrofísicode Javalambre (OAJ), situated at Teruel, Spain, uses an 83cm telescope to achieve a powerful 3D view of the nearby universe. It has 12 passbands photometric data that is designed to extract the spectral features. J-PLUS has a wide range of astrophysical applications.
A recent study led by Dr Cunshi Wang, a PhD candidate from the National Astronomical Observatories of the Chinese Academy of Sciences (NAOC), applied a Support Vector Machine (SVM) algorithm to classify the J-PLUS first data release (DR1) catalog into star, galaxy, and quasar. In the classification, some abnormal objects are found.
This work has been published on Astronomy & Astrophysics on March 18, 2022.
Machine learning, a cross-disciplinary subject of statistics, optimization, and computer science, creates algorithms that can process data based on a well-chosen sample set with features. It can help find the potential patterns in large data. SVM is a classification method that creates a hyperplane based on the distance of each object to itself to divide the objects.
The distinction between stars and other objects is obscure due to the point-spread detection of J-PLUS, so the researchers classify them to provide convenience for researchers based on J-PLUS.
The training sample has been chosen from spectroscopy surveys including Large Sky Area Multi-Object Fiber Spectroscopic Telescope (LAMOST), Sloan Digital Sky Survey (SDSS), and VERONCAT - the Veron Catalog of Quasars & AGN (VV13) catalogs. The spectroscopy data carry more information than photometric observations and they are more precise than spectroscopy data. The SVM model using magnitudes as features has been chosen due to its high accuracy.
Machine-learning algorithms have higher accuracy when the object falls into the sample-dense space. The researchers constructed 12 3D density contours to approach the space and divided the J-PLUS DR1 catalog into interpolation and extrapolation.
The blind test is a method to validate the algorithm, and it shows that the accuracy of interpolation is 96.50%, and the stars have the highest accuracy (99.27%). The accuracy of extrapolations decreases to 79.1%, where the magnitude distribution of galaxies and quasars are different from the sample set.
The abnormal objects tend to be difficult to classify to each label, which means that they have roughly equal prediction probability to each label. The researchers found these objects, tested the Mahalanobis distance to each label, and listed 26 abnormal objects.
This work will supplement the J-PLUS catalog and provide a new method to screen abnormal objects. The contour method provides a new idea to control the predicting uncertainty.
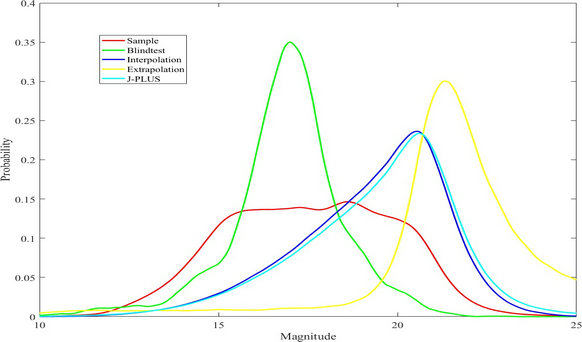
Figure: The magnitude distributions of label STAR. The legend 'J-PLUS' is the addition of interpolation and extrapolation. (Credit: Cunshi Wang)
This paper is available at https://www.aanda.org/articles/aa/full_html/2022/03/aa42254-21/aa42254-21.html

